At work we have started to set up new continuous integration servers. We have decided to build the whole setup based on into individual Jenkins instance managed via Docker. Moreover, most build slaves on the instances are dynamically-created Docker containers themselves. To spawn up these slaves, the Jenkins masters need write access to the Docker socket. Of course, this would be a security implication if they had access to the socket of the main Docker daemon on the host that operates all services, including the Jenkins instances themselves. Thus, we added a second daemon to the host just for the purpose of executing the volatile build slaves. However, we soon noticed that containers executed on this additional daemon frequently showed DNS resolution errors. The remainder of this post will explain the details of how we tried to track down this problem with all the ugly details being involved there.
Docker setup
I will first start to explain the details of the setup that we use, which is necessary to understand some parts of the bug hunt.
The server I am talking about is using Debian testing as its host system with Docker being installed using the provided Debian packages.
This daemon uses the automatically created docker0 bridge (plus some additional networks).
For launching a completely disparate daemon to be used for Jenkins slaves, a different bridge network is required.
Unfortunately, Docker itself cannot configure anything else apart from docker0:
The
-b,--bridge=flag is set todocker0as default bridge network. It is created automatically when you install Docker. If you are not using the default, you must create and configure the bridge manually or just set it to ‘none’:--bridge=none
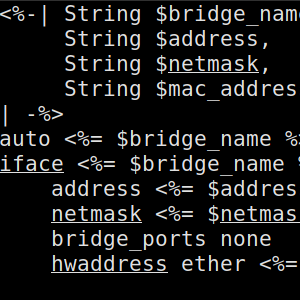
Therefore, we had to manually create a bridge device for this daemon, which we did using the Debian network infrastructure:
auto dockerbrjenkins
iface dockerbrjenkins inet static
address 10.24.0.1
netmask 255.255.255.0
bridge_ports none
Therefore, apart from separating the socket and runtime directories of the two daemons, one important difference is that the main daemon creates the bridge device on its own and the daemon for CI slaves uses a pre-created bridge.
Tracing it down
What we have observed is that from time to time builds in the spawned Docker containers failed with DNS resolutions errors. Thus, the first thing we did was to manually start a container on the same daemon in which we tried to count how often DNS resolution failed by frequently resolving the same host. This wasn’t very often. Out of 450,000 requests across a range of two days only 33 or so failed. This didn’t match the expectation, because build failures seemed to occur more often. However, at least we saw some errors.
Due to the manually created bridge network, the internal DNS server of Docker is not involved and the containers /etc/resolve.conf directly points to DNS servers configured on the host system.
Therefore, the first suspicion was that the configured DNS servers had sporadic problems.
Because of firewall settings, no external DNS servers could be reached for a comparison of error rates on the affected server.
However, executing the same long-running experiment directly on the host and not in a Docker container showed no resolution errors at all.
Therefore, the DNS servers could not be the reason and the problem was reduced to the affected host system.
One thing that was still strange with the experiment so far was the low error rate and the observation that most resolution problems in production appeared at night. This is the time were nightly builds were running on the Jenkins instances. Hence, I restarted the periodic DNS resolution task and triggered one of the nightly builds and it immediately became apparent that the running builds increase the chance for DNS resolutions errors.
In order to get Jenkins out of the issue, I tried to mimic what Jenkins does on the Docker side by starting a loop that frequently creates new containers and removes them shortly after again:
while true
do
echo "next"
docker -H unix:///var/run/docker-jenkins.sock run --rm debian:latest bash -c "sleep 2"
sleep 1
done
Creating and removing containers was sufficient to increase the DNS resolution errors again.
This was the point in time where we had the idea to replicate this setup to the main Docker daemon.
Interestingly, the same loop that constantly adds and removes containers didn’t affect DNS resolution on this Docker daemon.
Therefore, we somehow came to the conclusion that this must be related to the different network bridges used by the two daemons.
Of course, comparing all parameters of the bridges using ip addr, brctl, etc. didn’t show any important differences in the parameterization of the bridges.
Looking at network packages
In order to find out what is actually going on, another experiment we did was to record the network communication on the system using tcpdump.
Looking at the wireshark visualization of the packages you can see the following:
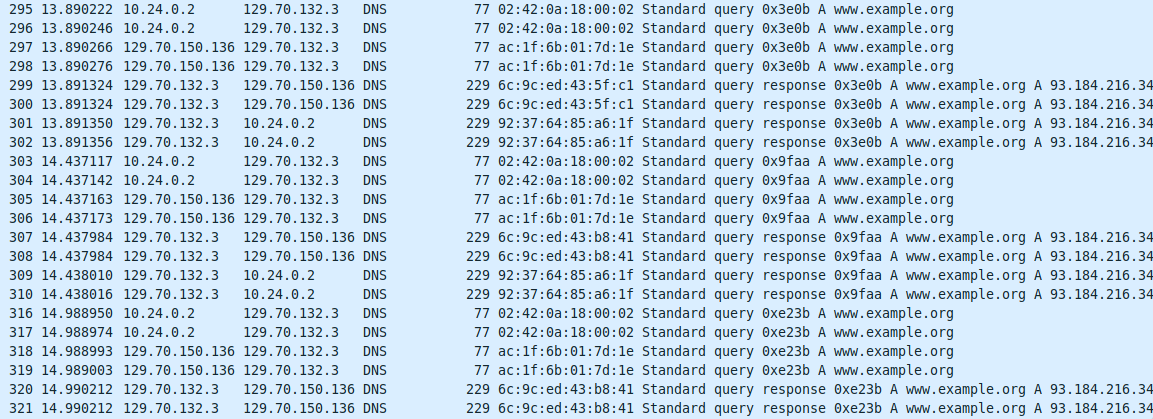
Package transmission pattern of successful DNS requests
So, what is visible here is that the packages are first sent from the container’s IP (10.x) to the DNS server and something remaps them to originate from the public IP address of the host system (x.136). These requests are then answered by the DNS servers and routed back the same way to the container. Packages appear multiple times due to recording all interfaces of the system.
In case of the unsuccessful request, the pattern of packages changes:
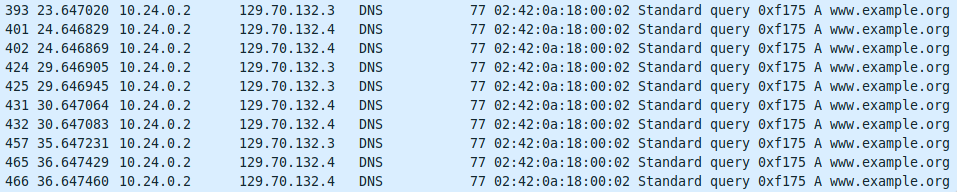
Package transmission pattern of failing DNS requests
Suddenly, nothing maps the requests to originate from the public IP address of the server and the requests never get replies. So, effectively the requests are stuck at the bridge network (10.x) and never reach the outer word. The DNS lookup then iterates all available DNS server, but with no success.
Why do are packages transformed the way visible in the first image?
Because the bridge device has no configured upstream interface and Docker itself instead configures iptables to perform NAT and forwarding.
This somehow seems to break down in case containers are added and removed.
Therefore, another suspicion we had was that Docker reconfigures iptables with every container change and this results in short outages.
So, we removed this possibility.
Removing docker iptables handling
Docker can be configured to not handle iptables at all using --iptables=false.
Hence, we set it up that way and configured the required iptables rules by hand instead via:
iptables -A FORWARD -o brtest -i externalinterface -j ACCEPT
iptables -A FORWARD -i brtest -o externalinterface -j ACCEPT
iptables -t nat -A POSTROUTING -j MASQUERADE -s 10.24.0.0/24 -d 0.0.0.0/0
However, nothing changed and DNS requests were still interrupted while containers were added and removed.
Completely eliminating Docker from the replication
As described before, the only real difference in terms of networking between the two daemons is how the bridge interface was created. Since we couldn’t find any real difference in the bridge properties, the next thing that we tried was to find out whether the issue could be reproduced with the bridge device itself and without any Docker involved.
So the first thing was to replace the loop spawning new temporary containers with something that replicates network devices joining the bridge and leaving it again.
This is what Docker does internally using veth devices.
Hence, the loop for interrupting DNS migrated to this one:
while true
do
echo "next"
ip link add vethtest0 type veth peer name vethtest1
brctl addif brtest vethtest0
sleep 2
brctl delif brtest vethtest0
ip link del vethtest0
sleep 1
done
brtest is the name of bridge device the daemon is using.
This was also sufficient to reproduce the observed DNS resolution errors.
The next step was to also remove the Docker container in which DNS resolution is tested and to replace it with something that limits the DNS traffic to the bridge device.
Here, Linux networking namespaces come into play.
Docker uses them internally as well.
Basically, the idea is to create a virtual namespace of network devices in which only a limited set of devices is visible to processes that are executed inside the namespace.
A virtual veth pair can then be used to attach to the bridge on the host side and to provide a single device that only communicates via the bridge in an isolated namespace for testing DNS resolution.
This way it is ensured that resolution never directly communicates with the outside world.
For easy replication, we have automated the whole setup and test through the following bash script:
#!/bin/bash
set -e
# teardown
function cleanup {
set +e
brctl delif brtest vethtest0
ip link del vethtest0
iptables -t nat -D POSTROUTING -j MASQUERADE -s 10.12.10.0/24 -d 0.0.0.0/0
iptables -D FORWARD -i brtest -o enp0s31f6 -j ACCEPT
iptables -D FORWARD -o brtest -i enp0s31f6 -j ACCEPT
ip link delete veth0
ip link set down brtest
brctl delbr brtest
ip netns del test
}
trap cleanup EXIT
ip netns add test
brctl addbr brtest
ip addr add 10.12.10.1/24 dev brtest
ip link set up dev brtest
ip link add veth0 type veth peer name veth1
ip link set veth1 netns test
brctl addif brtest veth0
ip link set up dev veth0
ip netns exec test ip addr add 10.12.10.42/24 dev veth1
ip netns exec test ip link set up dev veth1
ip netns exec test ip route add default via 10.12.10.1 dev veth1
# change external interface name
iptables -A FORWARD -o brtest -i enp0s31f6 -j ACCEPT
iptables -A FORWARD -i brtest -o enp0s31f6 -j ACCEPT
iptables -t nat -A POSTROUTING -j MASQUERADE -s 10.12.10.0/24 -d 0.0.0.0/0
while true; do ip netns exec test python3 -c "import socket; socket.gethostbyname('example.org')" && echo success; sleep 1; done
Even without Docker the errors still appear. This was the point where we basically gave up and requested help on the Linux netdev mailing list.
The solution
Fortunately, Ido Schimmel soon had an answer to the request:
The MAC address of the bridge (‘brtest’ in your example) is inherited from the bridge port with the “smallest” MAC address. Thus, when you generate veth devices with random MACs and enslave them to the bridge, you sometimes change the bridge’s MAC address as well. And since the bridge is the default gateway sometimes packets are sent to the wrong MAC address.
So the culprit here was to not assign a fixed MAC address to the manually created bridge device. The default behavior of constructing a MAC address from the (potentially changing) attached ports is actually pretty unexpected to us and I wonder what the original motivation for this was. However, with this information, network communication is finally stable.